Overfitting and Data Splitting
Data and exploration

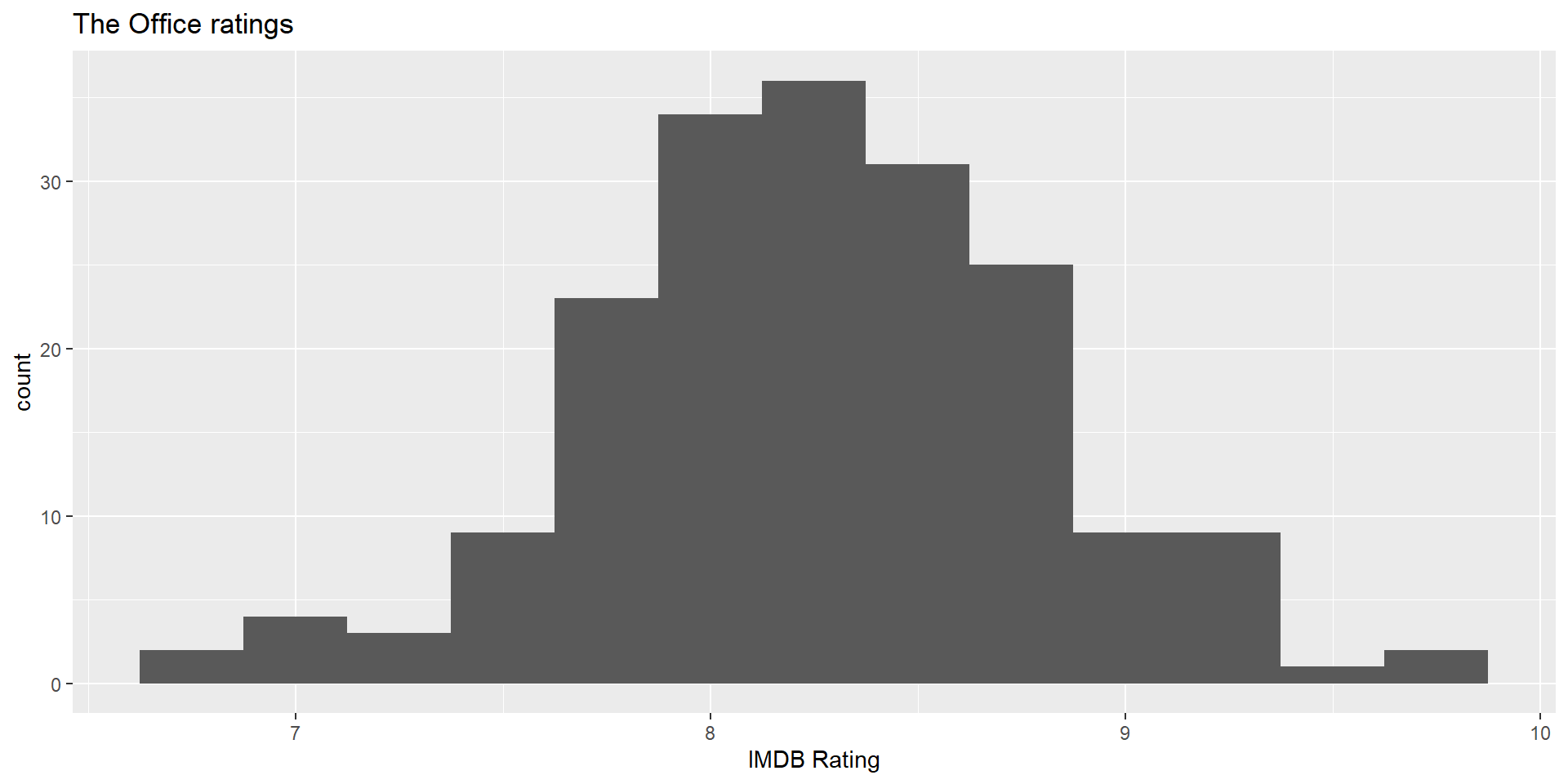
IMDB ratings
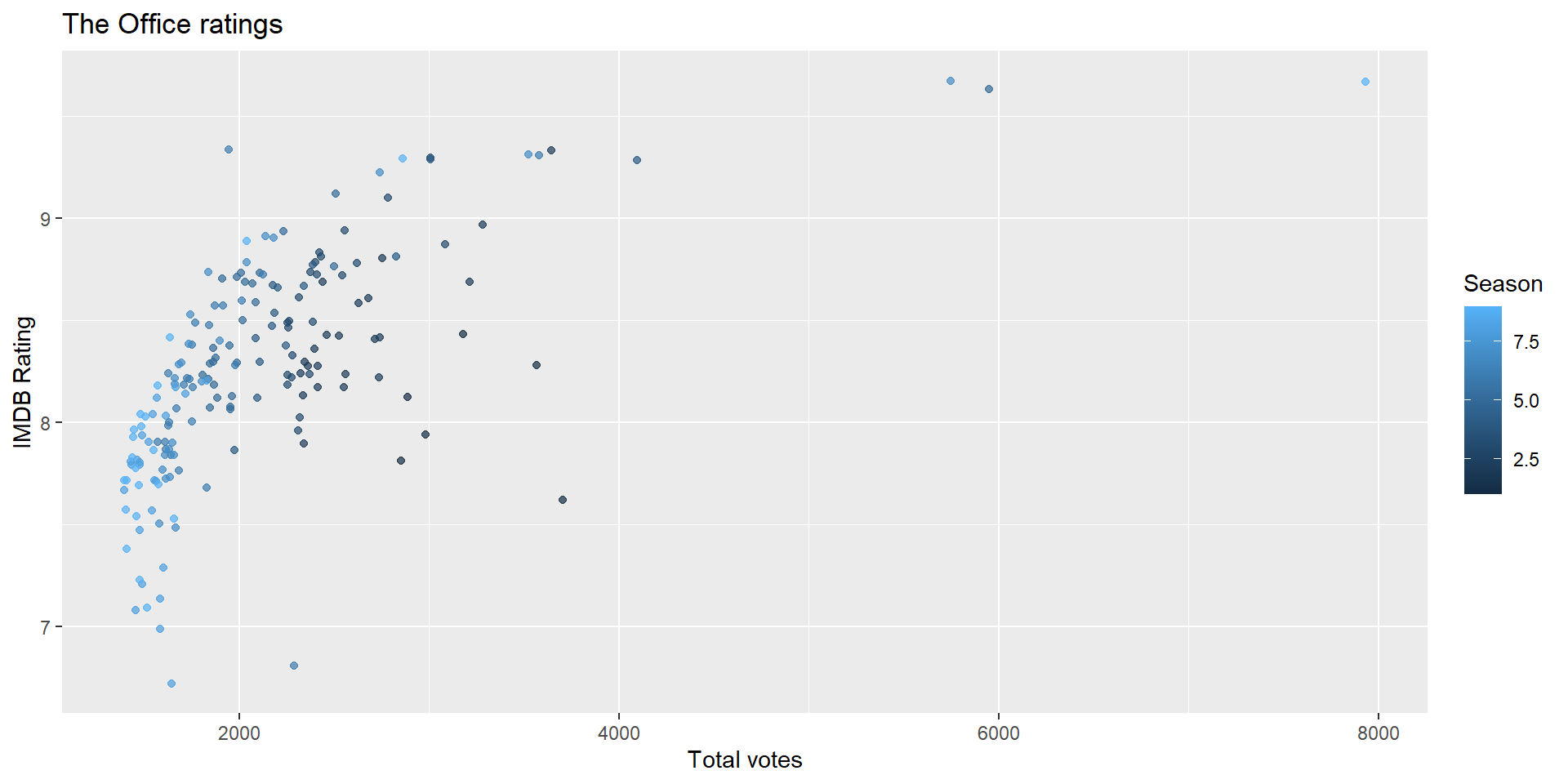
IMDB ratings vs. number of votes
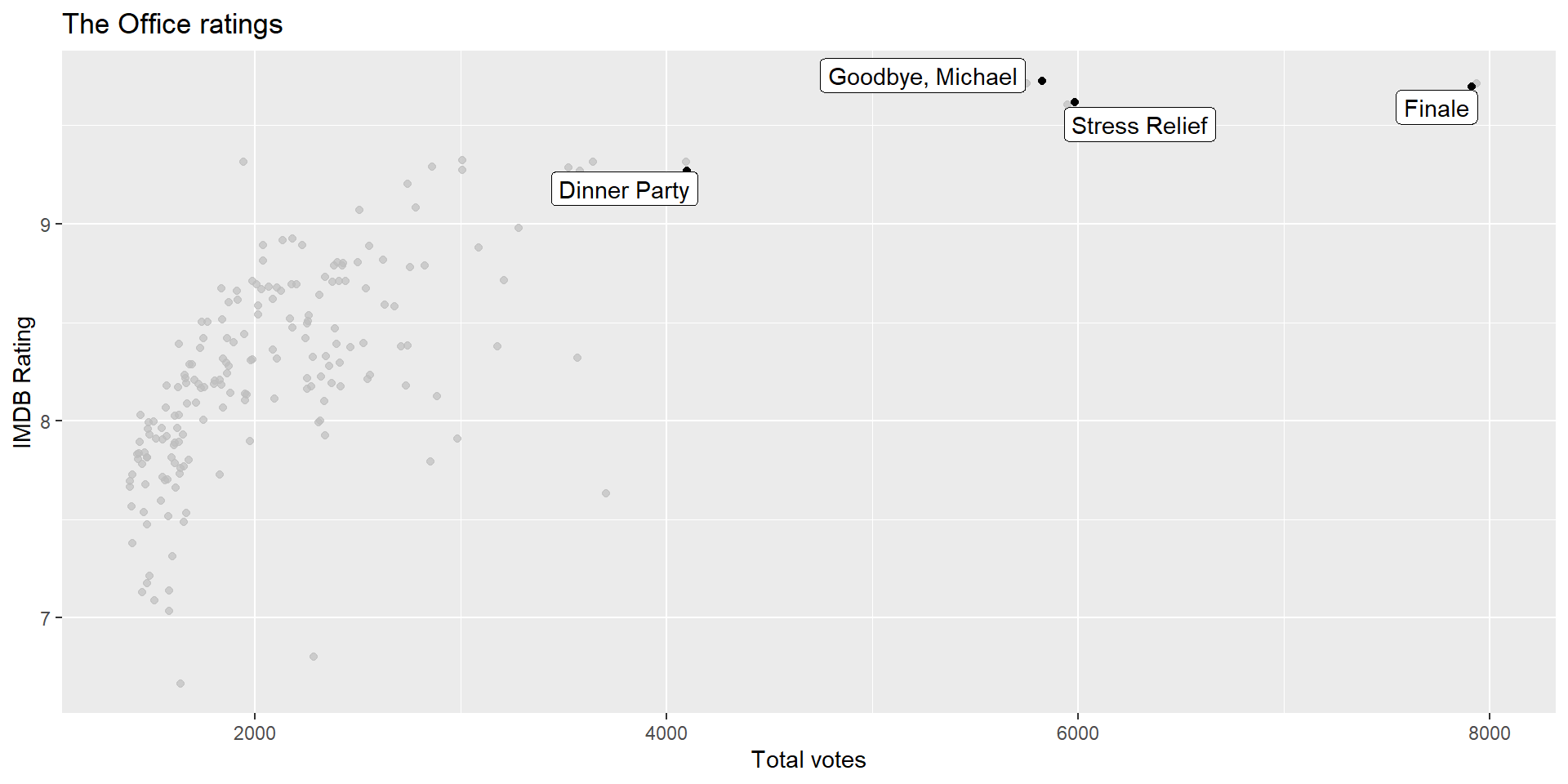
Outliers
If you like the Dinner Party episode, I highly recommend this “oral history” of the episode published on Rolling Stone magazine.
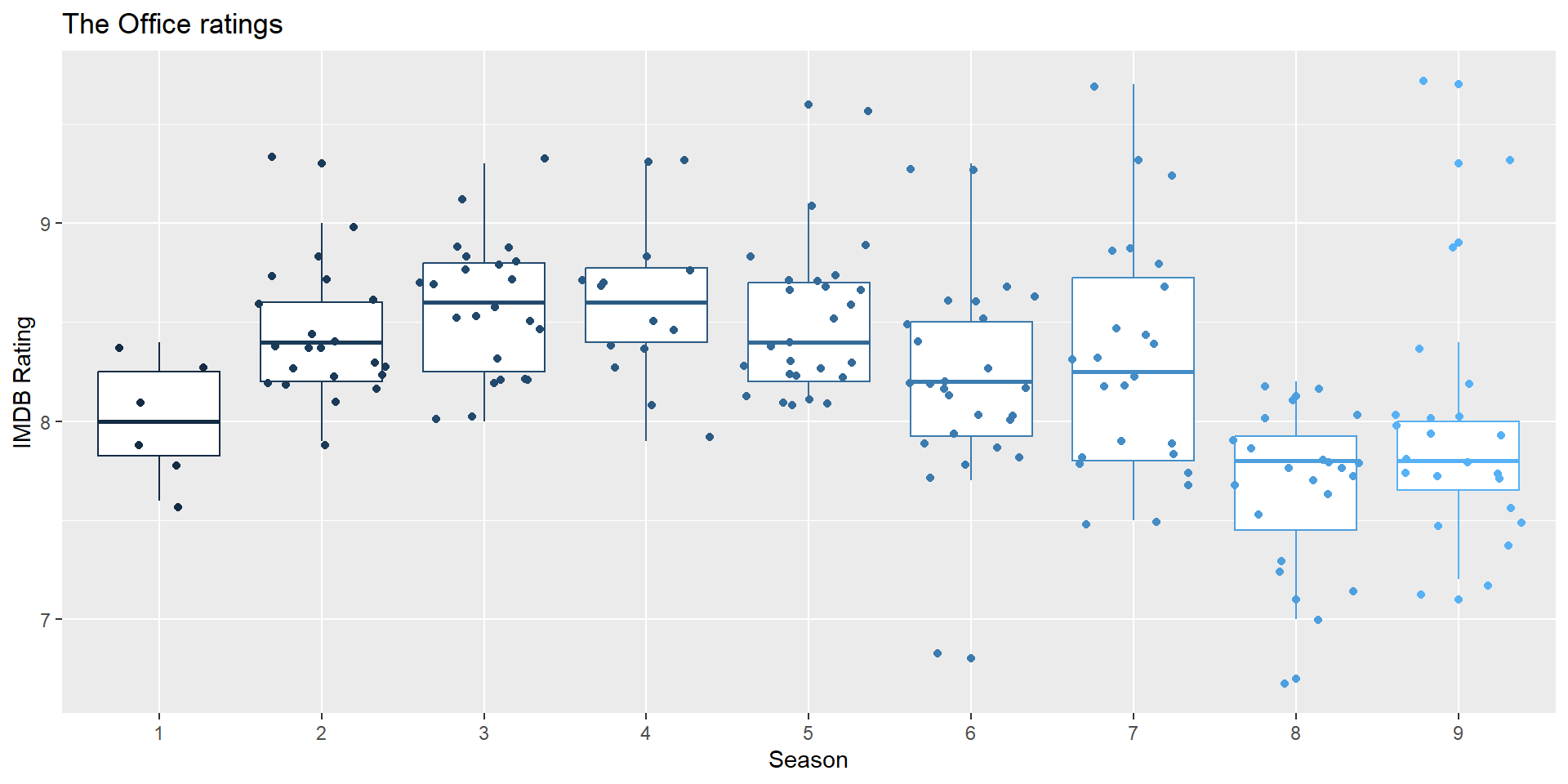
IMDB ratings vs. seasons
Evaluating performance on training data
The training set does not have the capacity to be a good arbiter of performance.
It is not an independent piece of information; predicting the training set can only reflect what the model already knows.
Suppose you give a class a test, then give them the answers, then provide the same test. The student scores on the second test do not accurately reflect what they know about the subject; these scores would probably be higher than their results on the first test.
Source: tidymodels.org
![]()